【转载请注明出处】chenrudan.github.io
随着计算硬件和算法的发展,缺乏有标签数据的问题逐渐凸显出来,不是每个领域都会像imagenet这样花费大量的人工标注来产出一些数据,尤其针对工业界,每时每刻都在产生大量的新数据,标注这些数据是一件耗时耗力的事情,因此,目前监督学习虽然能够解决很多重要的问题,却也存在着一定的局限性,基于这样的一个环境,迁移学习变的尤为重要。
针对迁移学习问题和域适配问题会分几篇文章来阐述,这里特别感谢王晋东同学,他整理了很多迁移学习入门的资料。本文主要整理了综述文章Transfer Learning For Cross-Dataset Recognition: A Survey[1]前面的一些基础入门内容。
背景
通常情况下我们都认为训练集数据和测试集数据分布来源是一致的,而且针对现在的一些深度学习算法需要大量的训练数据,但现实生活中往往数据的大量采集和标注是比较困难的,那么该如何解决这样的一个问题?反观我们人类,我们会在不同的问题中举一反三,例如一个弹过吉他的人再去学弹钢琴就会比没有任何乐理基础的人学的要快,或者一个人学会开汽车之后再去学习开卡车也会更加快,学会了数学之后学习物理也更容易,我们都是将之前学习到的某种东西运用到了新的任务之中,基于这样的一个想法,提出了迁移学习,即将其他的问题中提取出一些东西作用于需要解决的问题之上,从而提升未解决问题的性能。
针对迁移学习,有两个基本概念,一个叫域,包括两个内容,$D={X,P(X)}$,一是特征空间它代表了所有可能特征向量取值,一是边缘概率分布它代表了某种特定的采样。例如X是一个二维空间,P(X)为过原点的一条直线。
另一个概念叫任务,它也包括两个部分,$T={Y, f(x)}$,标签空间和预测函数,预测函数是基于输入的特征向量和标签学习而来的,它也称为条件概率分布$P(y|x)$。所以迁移学习定义如下,给定了源域源任务、目标域目标任务,利用源域在解决任务中获得一些知识来提升目标任务的这样一种算法。其中源域与目标域不相等或者源任务与目标任务不相同。也有论文将domain和task一起称为一个dataset,cross-dataset指的就是domain或者task不同。而这里域的不同可以分解为两个方面,一是特征空间不同,例如人脸的图片和鸟的图片样本空间就是不同的;或者是边缘概率分布不同,例如两个都是鸟类的样本空间,但是一个是在城市中拍到的鸟,一个是在大自然中拍到的。task的不同也体现在两方面,要么指的是标签空间不同,要么指的是条件概率不同,例如两个数据集数据分布不均衡。
迁移学习可以应用在很多问题之上。例如图1中的物体识别任务,实际上分类问题,这里是一组比较常用的数据集,主要拍摄对象是办公室用品,后三个来自三个不同源,分别是从亚马逊上下载的图片,用网络摄像头拍摄得到的低分辨率图片,用高分辨率相机拍摄得到的高分辨率图片。Caltech-256是从谷歌上下载包含256个类个图片,与Office整合之后成了一个新的数据集。这个问题其实就是属于相同的样本空间但是不同的边缘概率分布。另外还有人脸识别、场景分类等问题。

分类体系
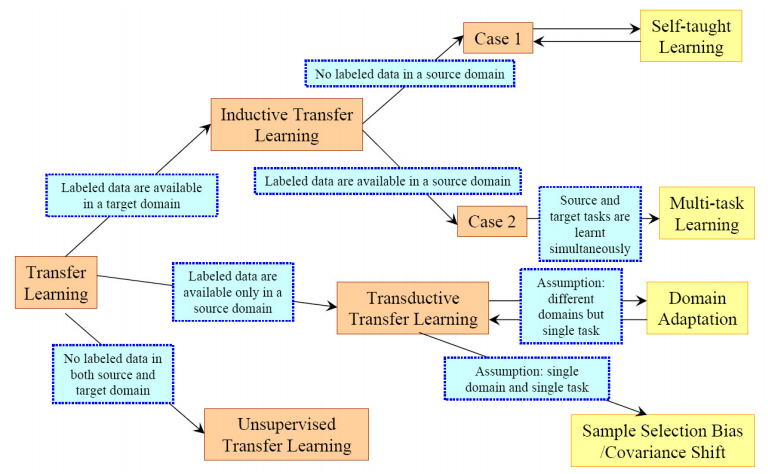
关于迁移学习有非常多种的分类,这里给出两种,首先基于不同迁移情况分为三类归纳式迁移、直推式迁移、无监督迁移,第一种归纳式针对的问题是源与目标域相同,但是任务不同,且此时源的标签可有可无,而目标任务是有标签的,比如imagenet数据训练好分类问题可以用来做回归,直推式迁移是源的域是不同但相关的,任务相同,且源域是有标签,而目标域没有,这里可以对应到上面提到的物体识别数据集,office-31,它的三个数据源用不同方式采集的,但是任务都是做分类。而无监督迁移学习,域和任务都是不相同但相关的,基本上处理的是一些聚类、降维、密度估计等问题。
| $D_S, D_T$ | $T_S,T_T$ | 源域标签 | 目标标签 | |
|---|---|---|---|---|
| 归纳式迁移学习 | 相同 | 不相同但相关 | 有/无 | 有 |
| 直推式迁移学习 | 不相同但相关 | 相同 | 有 | 无 |
| 无监督迁移学习 | 不相同但相关 | 不相同但相关 | 无 | 无 |
第二种分类方式是基于解决方法,也就是迁移内容来分的。样本、特征表达、参数、相关知识都可以用来迁移。首先是迁移样本,这个方法一般都是将source的样本融入target当成target的加权样本直接用于训练,通过一些算法来调整source样本的权重,当source和target的P(Y|X)是一样的时候,这种方法效果很好。其次是迁移特征,迁移特征有两种方式,第一种类似迁移样本,将特征调整权重之后加入target进行训练,第二种是建立source和target的特征关联,可以用某种映射减少源和目标的差异。再次是迁移参数,在source和target之间进行参数共享或者组合多个source模型来解决target的问题。最后是迁移知识,这里的知识代表的是数据之间存在的某种关联,source中有,那么希望将这个关联迁移到target中,且源和目标数据都是独立同分布的。
根据上面的分类,常常会将迁移学习划分成几种特定的问题。例如自我学习,它的source没有标签但是数据非常多target有标签但是用来做训练集数量不够,要利用源的信息可能就需要源采用稀疏编码等方式得到一种特征表达,再用到target任务上。这里的多任务学习与含义有一点区别,这里多任务的目的还是还提升target的性能,而不是要同时提升两者的性能。又或者域适配问题,域不同但是任务相同。
计算准则
这里总结一下一些比较典型的计算准则。
统计准则,实际上就是利用一些算法减少源和目标数据分布之间的差异,不管是迁移样本还是迁移特征表达都能用到这种准则。下面截取了论文[1]中的一些常见的方法。

互信息中的X代表了source和target的样本数据,Q代表了是哪个domain,例如0为source,1为target。q指的是某个样本分配到source或者target的后验概率,q0是域的先验概率。通过减少数据实例和label的相互关联,从而让不同域之间差异减小。而实际在论文中用的非常多的还是最大平均偏差,主要就是通过一个kernel将原始数据映射到了再生核希尔伯特空间,在这个空间中减小期望之间的差异。
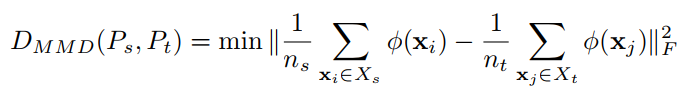
几何准则,是基于子空间的几何性质来建立不同的domain之间的关系。子空间可以通过特征提取、降维等方式获得。例如子空间对齐,先用PCA降维得到子空间,然后找到子空间中的一个线性映射将source和target的子空间坐标系对齐。还有中间子空间方法,意思是在格拉斯曼流形中,source和target的子空间是这个流形中的点,通过连接它们之间的测地线,然后在测地线上进行采样来得到一些中间子空间,然后将source和target的数据投影到中间子空间中来缩减两者的差异。例如图5的流形对齐,Ks和Kt是全邻接矩阵,矩阵每个元素代表样本i和j的距离,要学习的是F和A,A是数据集的线性投影,F是一个01矩阵代表了对齐源和目标的哪些样本,J是保持domain结构的流形。
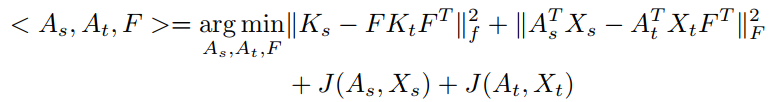
高级表示准则,就是找到一种更高级的表达能够找到数据集之间的不变性,一种通用的表达。例如之前提过的稀疏编码,这种方法一般是用于source没有标签的情况,通过重构样本以及限制编码中非零取值个数不超过T来得到一组基称为dictionary,这个dictionary就是在两个domain之间都可以使用的,得到target的稀疏编码,如图6中式子。还有低秩表示,找到一个子空间A使得target的样本能够由source样本线性表示,以及基于深度神经网络,用深度网络来学习一些可迁移的特征。另外还有栈式去噪自编码,通过编码器和解码器重构原始数据得到映射参数,共享参数到target得到特征表达,即优点在于能找到一些隐藏因子来保证domain之间的不变性。
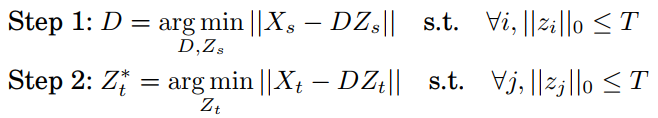
匹配准则,主要是基于domain之间有成对的样本来构建一种关系,例如从不同角度拍下的同一物体可以认为属于两个domain。例如匹配稀疏编码,成对的样本强制的共享同样的稀疏编码,此时与上面的稀疏编码不同的是共享的是Z,而上面共享的是D,所以没有共享基,而是共享了稀疏编码。匹配流形对齐,在映射矩阵的作用之下仍然保持一一对应的关系,前面的流形对齐未知源和目标的一一对应关系,所以需要学习一个矩阵F,而这里是已知这样的关系,所以直接优化。
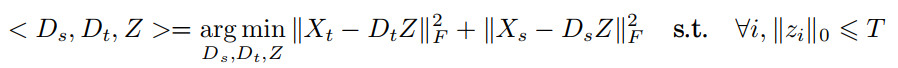
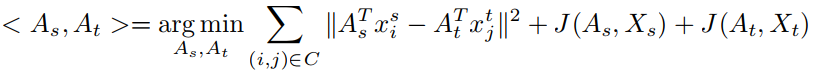
基于类的准则,利用标签信息将domain联系起来,这里就假设了每个domain都有label。例如度量学习,让相同label的样本距离缩小,让不同label的样本距离增大。线性判别模型,用source分类器参数来调整target分类器参数。
自我标注准则,主要针对target数据没有标签的问题,通过source数据来初始化target模型的参数,基于这样一个模型可以得到target模型的一个伪label,再用EM算法迭代的优化target模型。
小结
迁移学习本质需要解决的问题是如何让模型泛化能力更强,当在一个较大的数据集上训练好模型之后能够用到新的数据集中,如果两个数据集差异太大,迁移效果可想而知会比较差。所以迁移学习里有一个比较核心的问题是如何缩小不同域的差异,后续会针对这个问题来介绍几篇文章。
[1] Transfer Learning For Cross-Dataset Recognition: A Survey