【转载请注明出处】chenrudan.github.io
前一篇文章中的图2给出了迁移学习中几种常见的问题,其中一个比较重要的是域适应问题domain adaptation,域不同但任务相同,且源域数据有标签,目标域数据没有标签或者很少数据有标签。例如下图四个数据集,它们从不同的方式采集办公室用品的数据,任务全是做图片分类,且在做迁移任务时,它们分类的类别数标签是一致的。本文主要介绍几篇基于卷积网络的迁移学习文章的大致思路。

解决Domain adaptation问题主要的思路就是将source训练好的模型能够用在target上,域适配问题最主要的就是如何减少source和target不同分布之间的差异。域适配包括无监督域适配和半监督域适配,前者的target是完全没有label的,后者的target有部分的label,但是数量非常的少。这里主要介绍基于深度学习的方法,在我们已知finetuning之后,其实很容易想到,将在有标签的域A上训练好的模型用在无标签或者少量标签的域B上,中间的操作只需要改变输入,但是这种方式就会由于域A和域B数据分布不同导致效果并不一定会非常好,如果有方式能够减少A和B的差异,那就可以用同一个模型来跑A和B的数据。
DeCAF[2]
现在经常使用的fine-tuning这种trick,实际上最早也用来解决过迁移学习问题,属于基于特征迁移的方式。DeCAF[2]是Caffe的前身,文章是想从一个已经训练好的物体识别深度卷积网络中提取特征,将特征用到其他的数据集和问题中看效果如何。文章首先讨论了卷积不同层提取的特征到底表现如何,在ILSVRC-2012训练集上训练之后,提取了验证集不同层的特征来做t-SNE聚类,对比了两种算法提取的特征可以看到比较深的卷积之后的特征能够将不同的类区分开。从这个结果上看,卷积网络高层提取出的特征确实更加有区分性。
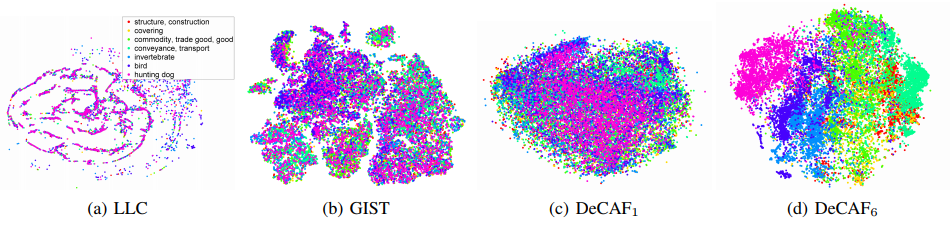
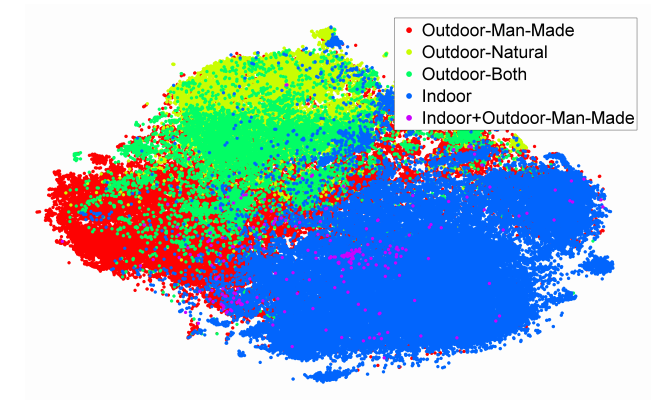
然后作者将在ILSVRC-2012上训练的网络,提取了数据集SUN-397的高层卷积特征,同样可以看到聚成了比较明显的几类,说明在Imagenet上训练好的网络对于SUN-397数据同样适用。
接着作者又尝试了在图1中的三个数据集Amazon、Webcam、Dslr进行了域适应任务,例如在Amazon上训练了卷积网络,再将网络用于Webcam提取特征,这样的方式比之前的特征提取方法分类准确率高很多,这里说明了基于卷积网络提取的特征在不同的域之间能够提取出一定的具有共性的特征。
DDC[3]
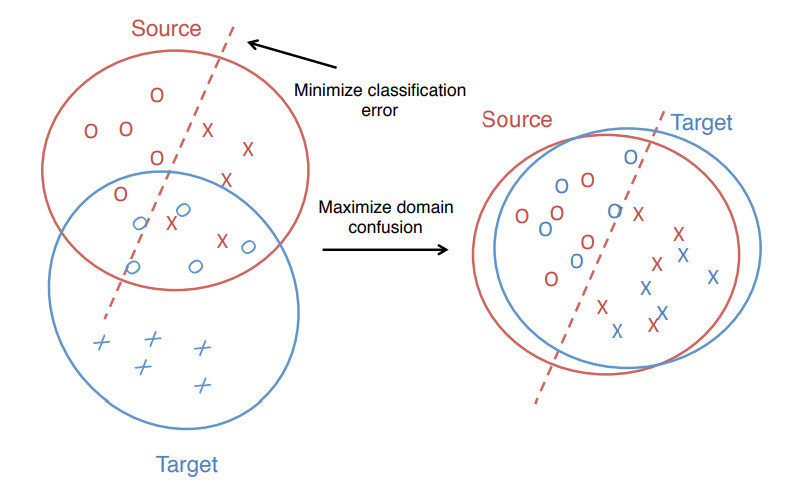
上面这种fine-tuning的方法针对已经训练好的模型在新的数据进行重新训练训练虽然能够起到一定作用,但是由于不同域的数据分布存在不同,如图4左侧图所示,source训练好的分类器在target不一定适用,因此Deep Domain Confusion这篇文章出发点是想在训练的时候能够同时减小source和target分布的差异,来让网络学习到更有迁移性的特征,如图4右侧图所示,缩小了差异学习到分类器同时适用于两个域。之前在神经网络中减少不同域差异的一些方法会采用下面的方式,使用一个固定已经有很强表达力的CNN,然后用MMD来决定用哪个层能够最小化domain差异,再用缩小了差异的特征表达去做分类。但是这种方式并没有让卷积网络起到最大的作用,实际上可以同时优化特征提取和分类两个问题。
因而DDC具体做法是在神经网络中额外加入一个适配层和域误差损失来自动的学习一些特征表达。主要还是利用MMD,假设映射函数为$\phi$,可以采用的优化目标如下,第一项是优化监督分类器,第二项是缩小domain之间的差异。
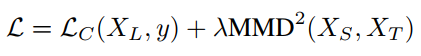
作者从直觉上觉得维数低的层能够让分类器更加正则化减少过拟合,所以增加了一个维数较低的适配层,为了增加这个层,就需要解决两个问题,一是在网络的什么地方增加一个是这个层维数取多少。第一个经过计算source和target在网络的不同层的特征表达之间的MMD数值,最后确定放在了fc7。第二个通过网格搜索来解决,在多层网络上用不同维数的层来进行微调然后计算新的低维层之间的MMD数值,最后选择最小的那个维数。图6中的网络参数是source和target共享的,分类的loss只有那些有label的数据会计算,所有数据都全部用来计算这个domain confusion loss。经过这样的优化,网络输出的特征不仅分类结果很不错,特征还具有了一定的迁移能力,学习到了一些域不变特征。
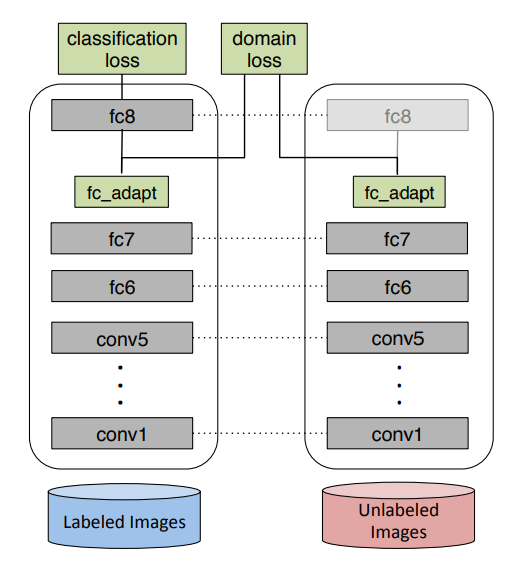
采用的数据集还是之前的办公室用品,分别从三个数据源采集得到31类,每个类利用了20/8/8张数据作为source,3张作为target,针对三个迁移任务进行了研究。比较了卷积网络中三个不同的全连接层的MMD取值以及对应的测试集准确率,其中取fc7时效果最好。还对比了MMD取值和acc随着加的适配层的维数变化而产生的不同结果,结论就是MMD能够帮助来选择放层的位置以及决定层的维数。然后在数据集上做了迁移的验证,分别是无监督任务和半监督任务,发现结果要远好于其他算法。最后还比较了一下从Amazon数据迁移到Webcam的任务中,加不加MMD这一项的结果对比,发现加入了MMD后迁移效果更好。(具体的图建议去看原文)
这篇文章优势在于能够选择适配层的维数,以及针对一个已经预训练好的网络找到放这个适配层的地方,且能够得到更好的特征表达。个人觉得这个文章的方法还是有点不够通用不够智能,换一个网络,可能就要不同的适配层的维数和放置的位置。但是毕竟是14年的文章,且开创了这样的思路,卷积网络能够学习到具有普适性和可迁移的特征,但是在高层的的特征还是依赖特定的数据集和任务,当减少domain之间的差别之后也的确增加网络高层特征的可迁移性。
DAN[4]
之前的两篇文章可以看出深度神经网络能够用在domain adaptation上,并且迁移的都是高层的特征,但是在实际的问题中迁移的效果往往会会由于domain的差别过大导致效果锐减,因此减少数据集的bias显得非常重要。上面的DDC研究出了在深度网络的中间一层加入MMD能够减少不同domain之间的差异,是否还有方法能更进一步的减少差异?
基于这样的考虑, Deep Adaptation Networks(DAN)这篇文章采用了两种改进方法,一是在衡量两个分布差异时使用多核MMD,二是不只选择一层网络来减少差异,而是选择多个全连接层。如图6中,在alexnet的全连接层fc6、fc7、fc8上来自不同域的数据产生的特征都进行了一一对齐。
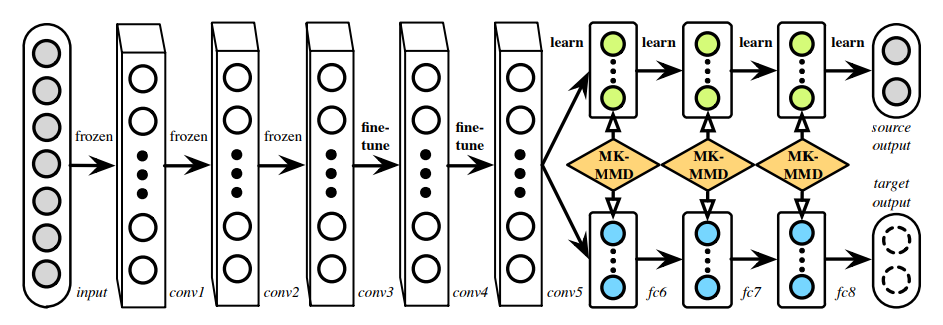
具体实现中采用了多核MMD,根据核技巧和多核的无偏估计,能够将复杂度变成$O(n)$,且可以正常使用SGD的方式来优化。
文章还是用了图1中的数据集,表中DAN7表示只用了fc7,$DAN_{sk}$表示用了多个层单核,从表中可以看出DAN方法远比其他算法好,同时也可以看出其实适应性在不同的算法中是不同的,比如DW比较相似所以它们之间进行迁移准确率更高。而且几种基于卷积网络的都表现的非常好,说明深度学习确实更能够学习到具有普适性和可迁移的特征。类似的DDC方法只利用了一个特征和一种kernel效果都不如多层特征和多种kernel的效果。其中只用了一层的DAN7也比DDC好也说明多个kernel效果好。后面针对DDC和DAN提取出来的迁移层特征做了t-SNE的聚类,发现DAN方法在target域上更能将样本分开,也说明了提取的特征更有效,这里就不列出来了。
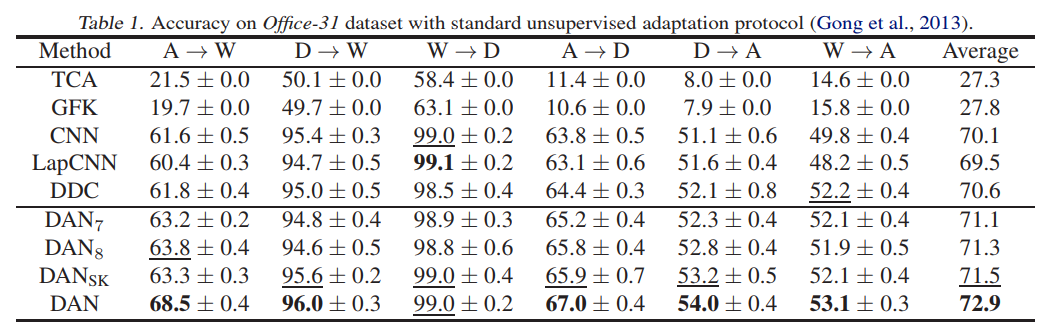
总的来说,DAN解决了之前说过DDC的问题,如何去高层特征中选一个层来最小化不同域的差异以及如何选择适配层的维数,这里就直接利用了靠近输出的每个高层,且在最小化MMD时使用了多核表达式,并且不再自己去增加一个适配层,而是直接用了正常网络中的所有全连接层。
JAN[5]
DAN的方法似乎已经将基于卷积网络的迁移加入了足够的约束,但是深度网络在训练的过程中所学到的特征由general变到specific,特征和label的联合概率分布的差异在高层的时候仍然存在。在DAN基础上同一批作者又提出了基于jointMMD将多个依赖domain特征层的分布进行对齐。如下图所示,将若干个高层特征做连乘得到它们的联合概率分布。横向表示一个神经网络从底层到高层的变化,中间的z就是每个中间层的特征表示结果。右边时候在网络中间加入了一个判模块络,这个模块的作用是对source和target进行二分类,即卷积网络在学习如何减小两个domain差异的参数,而判别模块则在尽量分辨出当前数据来源是source还是target,从而能让CNN学到更具有适配性的特征。
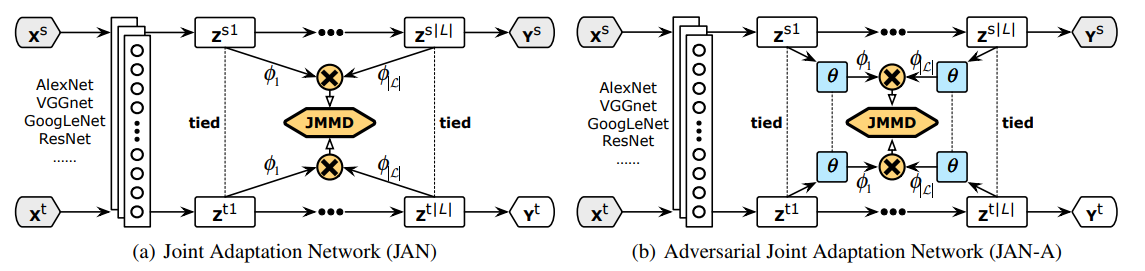
文章的出发点是认为domain的分布$P(X^s,Y^s)$以及$Q(X^t,Y^t)$可以通过中间层的分布来体现$P(Z^{s1},…,Z^{sL})$和$Q(Z^{t1},…,Z^{tL})$。所以可以推导出多层之间的联合概率分布差异如下。之前的文章还是在单独的缩小每一层的特征向量之间的差异,在这篇文章中更进一步,考虑到每一层的联合分布,来缩小这个联合分布。
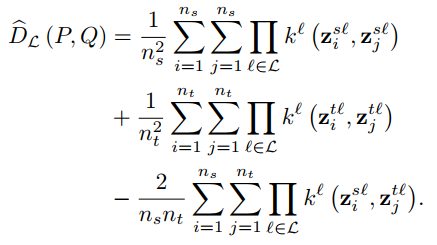
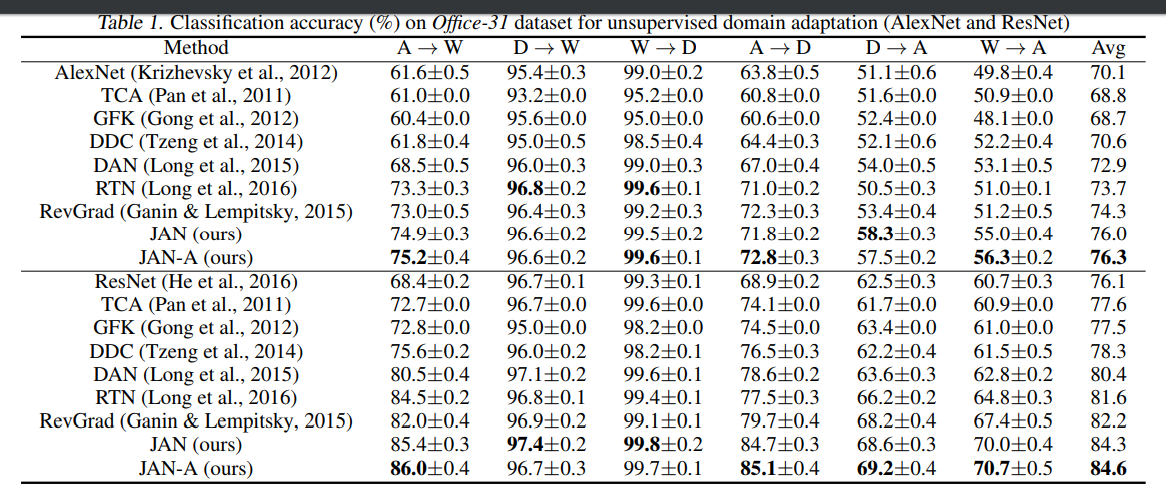
JAN的方法在大多数任务上都要优于之前的算法,且在一些比较困难的任务上,也效果非常好。从图11结果上来看,深层网络更能提取出有迁移性的特征,基于resnet的基本上都优于alexnet。基于神经网络提取特征的方法某些情况下能比传统方法好某些情况下不行,说明提出出来的特征确实有减小domain差异的能力,但是没做到完全去除差异,而这些基于神经网络加上了缩小domain差异的方法又比传统方法表现的更好,说明加上了缩小差异之后,神经网络能够学到有迁移性质的特征,但是这些方法只考虑了单层与单层之间的边缘概率分布的差异,由于JAN考虑到了全局的联合概率分布,即采用这样的联合分布更能学习到有迁移性的特征。其他的实验结果也是从各个方面证明了JAN可以使得源域和目标域分布差异更小。
小结
上面所列出的几种方法都是基于卷积网络来实现了迁移学习,从实验结果来看,确实都表现很好,但是从同事的口中却得知实际工程应用中其实效果并不好。我虽然没有实际使用迁移学习一些方法,但是从这几篇文章中也看得出一些端倪,文章所用的数据集主要是办公室用品那几个,都是几千张的样本,对于现在的很多任务来说算比较小了,所以迁移学习从理论到实践,还有一段长长的路要走。
[1] Geodesic Flow Kernel for Unsupervised Domain Adaptation
[2] DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
[3] Deep Domain Confusion: Maximizing for Domain Invariance
[4] Learning Transferable Features with Deep Adaptation Networks