【转载请注明出处】chenrudan.github.io
MobileNet[1]是谷歌出品的一个轻量级的神经网络结构,经过一年的发展逐渐成为类似GoogleNet、ResNet一样的基础性网络结构,它的出发点是想构造精简、轻量级的神经网络,可以在性能有限的移动端上运行。可以认为它是一种网络压缩的方法,但是不同于其他压缩模型的方法的是,它不是在一个大的网络上进行剪枝、量化、分解等操作,而是给出了一个新的网络构造。今年一月又推出了第二个更为优化的版本[2],具体的caffe实现可以参考[3]。
MobileNet v1
V1版本的核心是将正常的卷积分解为深度可分离卷积和1x1逐点卷积,正常的卷积假设输入M个feature map,输出N个feature map,卷积核的数量为MN,假设每个卷积核大小为33,M个卷积核与M个输入map对应卷积并累加得到一个输出map,再用新的一组M个卷积核与输入map卷积得到下一个输出map。卷积过程可以看成两个步骤,一是卷积核在输入图片上提取特征,二是将提取的特征通过相加的方式融合成新的特征。
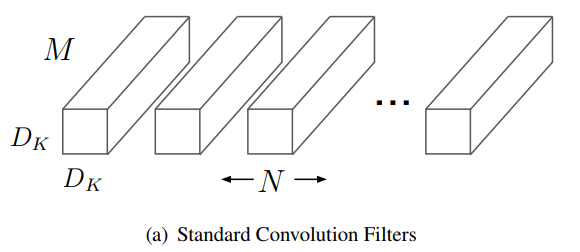
而mobilenet将传统卷积分解成了两个步骤,第一个步骤是深度可分离卷积DepthwiseConvolution,它只有M个33的卷积核,M个卷积核与M个输入map一一卷积得到M个map,它起到了提取特征的作用,第二个步骤是逐点卷积PointwiseConvolution,实际上就是传统的卷积,只是所有的卷积核都是11,一共有MN个11,起到了融合已提取特征的作用。
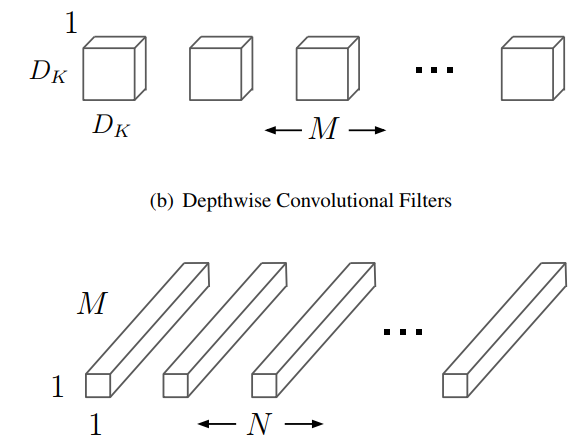
这个过程中减少的计算量是什么?实际上就是提取特征的filter个数变少了,1*1的卷积过程实际上也就是矩阵乘法,不需要im2col函数来整合成特征图矩阵和卷积核矩阵。所以在论文中,传统卷积和两步卷积对应的计算量对比如下,分母是传统卷积的计算量,分子是两步卷积的计算量。
$$
\frac{D_K\cdot D_K\cdot M\cdot D_F\cdot D_F+M\cdot N\cdot D_F\cdot D_F}
{D_K\cdot D_K\cdot M\cdot N\cdot D_F\cdot D_F}
= \frac{1}{N}+\frac{1}{D^2_K}
$$
而在实现上,传统卷积是一层就实现,分解后的卷积需要两次来实现,在DW卷积和PW卷积之后都接上了bn层和relu层。

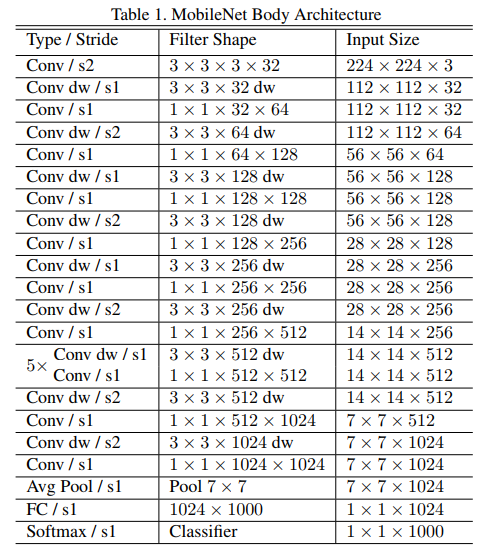
MobileNet一共有28层,整体的结构如下表所示。
此外,文章还定义了两个,第一个超参数是宽度乘子$\alpha$,通过它可以进一步减少计算量,它是一个缩放系数,原来卷积的输入输出channel乘以这个系数就是新的channel数量。第二个超参数是分辨率乘子$\rho$,它也是缩放系数,对象是特征图的大小,特征图尺寸乘以这个系数就是新的特征图尺寸。
实验结果上来看,文章在Imagenet数据集上的分类任务中对比了28层的传统卷积与MobileNet,在最终准确率降低较少的情况下,正常卷积的计算量和参数量分别是MobileNet的8.55倍、6.98倍。

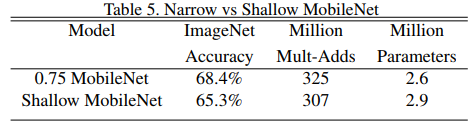
有意思的是文章对比了图6中窄的网络和浅的网络,从结果上来看,在两者计算量一致的情况下,窄的网络比浅的网络性能更好。
另外一个有意思的结论是文章统计了Imagenet分类准确率跟计算量和参数量之间的关系,最终发现与计算量、参数两都呈现了类似log函数的形式。
文章还在多种任务上都进行了对比测试,大部分的结果都表明了MobileNet能够在保证一定准确率的情况下极大的减少计算量。
MobileNet v2
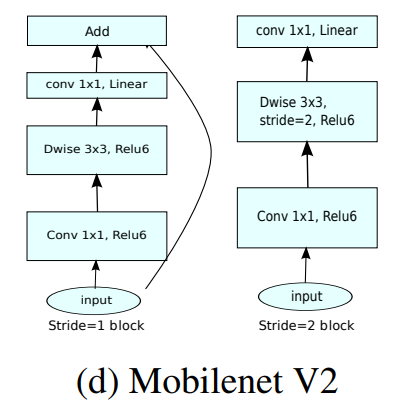
从上面v1的构成表格中可以发现,MobileNet是没有shortcut结构的深层网络,为了得到更轻量级性能更好准确率更高的网络,v2版本就尝试了在v1结构中加入shortcut的结构,且给出了新的设计结构,文中称为inverted residual with linear bottleneck,即线性瓶颈的反向残差结构。
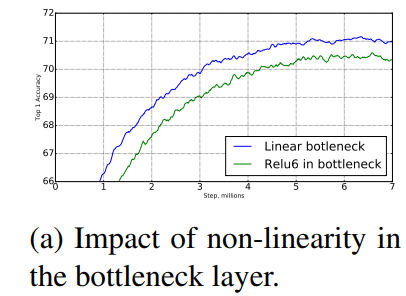
文章首先考虑了relu非线性函数的影响,我们知道relu函数只取输入的非负值,且认为这个行为导致了信息损失,而文章却给出了另一个结论。首先文章假设了每一层的特征图激活值形成了一种未知流形,虽然无法直接知道这个流形是什么,但是流形学习中最基本的想法就是高维数据能够映射到低维空间,因而这些激活值构成的流形也是能映射的。在神经网络中这种映射就体现在降低特征图的channel数,类似MobileNet v1中设置了一个超参数宽度乘子$\alpha$,但是问题是这个宽度因子如何选择?降低到多少channel数能够最大程度的保留所有的信息。映射到一个合适的低维空间即等价于通过这个乘子降低到合适的channel数,且作者认为在宽度乘子作用下能够使得激活值形成的低维流形能够占满整个低维空间。就是在这个条件之下,文章通过公式证明了只有在激活值能够得到输入空间的一个低维流形时,relu函数才能够保留完备的信息。这是第一个性质,另外一个性质是当输入都是非负值时,就算经过relu变换,本质上还是线性变换,这点是显而易见的。
这个性质表明了激活值的channel数量较少时,relu无法保留完备的信息,会丢失很多信息,所以这种情况下不适合用relu,如图7所示,将原始二维信息,经过一个矩阵映射到高维空间中,再经过一个relu,反向映射回原始二维空间,由于原始的二维空间是n=15,30的低维流形,而不是n=2,3的低维流形,所以在n=2,3时信息丢失较多。

基于上述结论,文章提出了linear bottleneck layer,这个结构有三个卷积操作,即先通过1*1的PointwiseConvolution来提升channel数,再接一个DepthwiseConvolution,最后再用PointwiseConvolution将channel数量降下来。Bottleneck就体现在最后的这个降低channel数的PointwiseConvolution,根据之前对relu的研究,这种维数较低的channel之后再加relu会损失信息,所以linear则体现在最后的PointwiseConvolution之后不像之前一样接relu了。
从实验结果上来看线性层确实能够防止非线性破坏过多的信息。
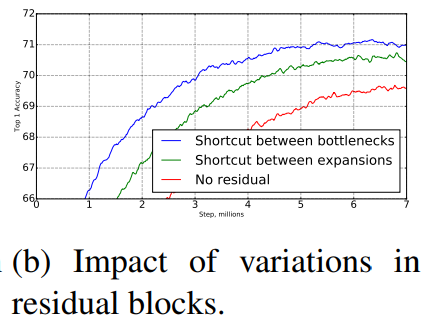
为了获得更强的深层反向梯度传播能力,在v2版本中加入了shortcut连接方式,inverted residuals的inverted体现跟resnet相反的设计方式,传统的resnet模块,往往会将输入channel先用PointwiseConvolution降低,执行了正常的卷积操作之后再用PointwiseConvolution将channel增加还原,而本文的设计则跟这个方式刚好是反的。图10的结果中也可看出加入shortcut连接性能提升很多。
结合上述两个创新点之后,MobileNet V2的整体结构如图11,其中每一个bottleneck的结构如图8所示。

小结
有人说MobileNet没有创新点,有人说MobileNet是业界良心,个人觉得MobileNet是一个非常棒的网络,虽然很多东西不是它原创的,但是两个版本的实用性都非常强。
[1] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[3] MobileNet-Caffe