【转载请注明出处】chenrudan.github.io
本文是gpu编程系列第二篇,主要谈谈CUDA软件层面的一些内容,这里的软件层面是指用户写程序涉及到的一些内容,包括介绍CUDA、区分Runtime API与Driver API以及介绍一些常用的库,最后谈一谈NVCC的编译流程。
1. CUDA是什么?
接触过gpu编程的人肯定都会看到过一个词CUDA,全称是Compute Unified Device Architecture,英伟达在2007年推出这个统一计算架构,为了让gpu有可用的编程环境,从而能通过程序控制底层的硬件进行计算。CUDA提供host-device的编程模式以及非常多的接口函数和科学计算库,通过同时执行大量的线程而达到并行的目的。在上一篇讲gpu硬件的文章中提到过流处理器(SM)的概念,并且说过SM是gpu的计算单元,而线程是执行在SM上的并行代码。CUDA也有不同的版本,从1.0开始到现在的7.5,每个版本都会有一些新特性。CUDA是基于C语言的扩展,例如扩展了一些限定符device、shared等,从3.0开始也支持c++编程,从7.0开始支持c++11。
在安装CUDA的时候,会安装三个大的组件[1],分别是NVIDIA驱动、toolkit和samples。驱动用来控制gpu硬件,toolkit里面包括nvcc编译器、Nsight调试工具(支持Eclipse和VS,linux用cuda-gdb)、分析和调试工具和函数库。samples或者说SDK,里面包括很多样例程序包括查询设备、带宽测试等等。
2. Runtime API vs Driver API
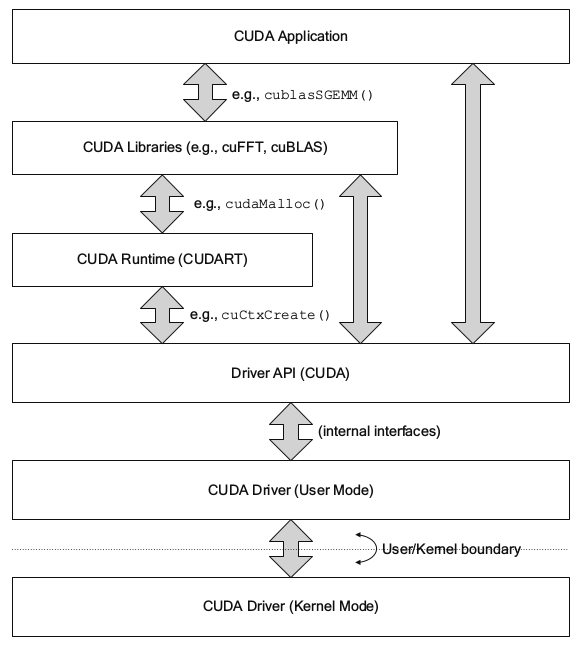
在写cuda程序时,除了自己写的kernel函数,常常会调用cuda接口函数,最常见的就是全局内存分配函数cudaMalloc(),这里分配的内存暂且理解为gpu硬件参数上的显存。然而在某种情况下可能会看到另外一个函数cuMemAlloc(),这两个函数本质上完成的功能是一样的,都是在分配全局内存,但却属于两套接口,分别为Runtime API和Driver API。下图是cuda软件层的一些组件,实际上在cuda的软件层面,Runtime比Driver API更高级,封装的更好,在Runtime之上就是封装的更好的cuFFT等库。这两个库的函数都是能直接调用的,但Driver API相对于Runtime对底层硬件驱动的控制会更直接更方便,比如对context的控制[2],Driver API调用硬件速度实际上比Runtime也快不了多少。不过Driver API向后兼容支持老版本的,这点Runtime就做不到,7.0的版本代码可能在6.5上就跑不了。大部分的功能两组API都有对应的实现,一般基于Driver API的开头会是cu,而基于Runtime API的开头是cuda,但基于Driver API来写程序会比Runtime API要复杂,虽然功能上差别不大,但是使用Runtime API和更高级的库函数就已经足够了。
3. 常用函数库
NVIDIA针对cuda的使用开发了很多好用的库,包括实现c++ STL的thrust、实现gpu版本blas的cublas、实现快速傅里叶变换的cuFFT、实现稀疏矩阵运算操作的cuSparse以及实现深度学习网络加速的cuDNN等等[3]。在操作这些库时有一个通用的规范,即调用者进行设备内存的分配与释放,内存分配好后将指针传递给这些库接口,就可以进行计算了。
关于thrust,它最基本的数据类型是两个向量容器,host_vetcor和device_vector,分别对应了内存分配在cpu内存和cpu内存,并且提供了非常多的函数模板,例如归约、归并、排序、二分查找等等。此外支持很多STL容器,例如下面的例子(代码来源[4])中即可以从c++容器中将数据复制给thrust的vector,也能将thrust的数据复制给c++ stl。
std::list<int> stl_list;
stl_list.push_back(10);
stl_list.push_back(20);
stl_list.push_back(30);
stl_list.push_back(40);
// 从c++ stl的list来初始化device_vector
thrust::device_vector<int> D(stl_list.begin(), stl_list.end());
// 将device_vector的内容复制到stl的vector中
std::vector<int> stl_vector(D.size());
thrust::copy(D.begin(), D.end(), stl_vector.begin());而cublas的接口设计基本上跟blas库是一致的,也是有lever1~3的接口,不同点在cuda的库风格是在使用相关函数之前要创建一个句柄,这个句柄也要传递到相关函数中去,在程序完成之后要销毁对应的句柄。因此cublas库函数原型比blas的参数要多。句柄的设置是为了方便执行多gpu,即在通过调用cudaSetDevice()来启用不同的gpu设备,在每个设备上又可以初始化一个独立的句柄,那么就能同时在多个gpu上执行。虽然cuda允许不同的线程调用同一个句柄,但是最好还是不要这样做。
至于cudnn,它是专门针对深度学习实现的一个库,目前主要还是实现卷积神经网络,加速效果很好,现在的一些深度学习框架基本上都支持它。
4. NVCC编译流程
由于程序是要经过编译器编程成可执行的二进制文件,而cuda程序有两种代码,一种是运行在cpu上的host代码,一种是运行在gpu上的device代码,所以NVCC编译器要保证两部分代码能够编译成二进制文件在不同的机器上执行。nvcc涉及到的文件后缀及相关意义如下表[5]。
| 文件后缀 | 意义 |
|---|---|
| .cu | cuda源文件,包括host和device代码 |
| .cup | 经过预处理的cuda源文件,编译选项--preprocess/-E |
| .c | c源文件 |
| .cc/.cxx/.cpp | c++源文件 |
| .gpu | gpu中间文件,编译选项--gpu |
| .ptx | 类似汇编代码,编译选项--ptx |
| .o/.obj | 目标文件,编译选项--compile/-c |
| .a/.lib | 库文件,编译选项--lib/-lib |
| .res | 资源文件 |
| .so | 共享目标文件,编译选项--shared/-shared |
| .cubin | cuda的二进制文件,编译选项-cubin |
此外编译的常用选项还有--link,编译并链接所有的输入文件,--run编译链接文件后直接执行,-m指定32位还是64位机器。
有时还会见到--gpu-architecture/-arch和--gpu-code/-code,它们的目标是为了让gpu代码能够兼容多种架构的gpu,它们的取值范围是一样的包括compute_10/compute_11/…/compute_30/compute_35/sm_10/sm_11/…/sm_30/sm_35,这些取值范围的意义实际上是指gpu的计算能力,或者是SM的版本,一般表示的是1.0/2.0/3.5这样的,具体体现在之前讲过的kepler/fermi的不同架构,所以两者实际含义是一样的(这里看[5]上表达应该是两者等价,但是为什么要搞两个,统一叫计算能力不行吗…)。而这里两个编译选项都要选择计算能力/sm版本,这是因为nvcc最后生成的可执行文件可以同时存在多个版本(对应compute_10/…/compute_35等)的kernel函数,这多个版本就通过这两个编译选项确定。这两个编译选项使得中间会生成的ptx文本文件和cubin二进制文件,它们指定了最后生成的可执行文件中可以满足的版本要求,即通过-arch指定ptx将来可以生成怎么样的版本(可以看成针对一个虚拟的gpu),而-code参数是指当前就要生成的二进制的版本(可以想象成一个真实的GPU),当前和将来的意思是指,最后生成的可执行文件中一个部分是马上就能在gpu上执行,而如果gpu硬件版本不支持这个能够马上执行的部分,那么显卡驱动会重新根据ptx指定的版本再生成一个能够执行的可执行版本,来满足这个gpu的硬件需求。它们的版本信息会先嵌入fatbin文件中,再通过fatbin与host代码编译生成的中间结果链接成最后的目标文件,这是针对一个.cu源文件生成一个.o文件,再将不同.o链接成可执行文件,那么这个可执行文件中就包含了多个版本的信息。假如取–arch=compute_10 –code=sm_13,在最后的可执行文件中,就有一个可以直接执行1.3的版本,假如此时gpu计算能力只有1.0,那么驱动会再次编译生成1.0版本的可执行文件,这个新的可执行文件就能在计算能力只有1.0的机器上运行了,从而通过这样的方式可以兼容不同计算能力的gpu。需要注意的是code的版本要高于arch。
显然这里有一个问题,一般而言生成的c++可执行程序就直接执行了,不会再有编译的过程,但是cuda不一样,它有一个机制叫做just-in-time(JIT,运行时编译),为了满足两种执行cuda程序的方式。第一种就是直接执行cubin版本,第二种就是显卡驱动通过JIT在运行的时候根据ptx版本再次编译生成可执行文件。
NVCC实际上调用了很多工具来完成编译步骤(建议先看看[5]中完善的流程图)。在编译一个.cu源文件时,当输入下面的指令后,执行程序就会将整个编译过程都打印出来。cuda的整个编译流程分成两个分支,分支1预处理device代码并进行编译生成cubin或者ptx,然后整合到二进制文件fatbin中,分支2预处理host代码,再和fatbin一起生成目标文件。
nvcc --cuda test.cu -keep --dryrun针对打印出来的每个过程中生成的文件做一个简单的分析,test.cu初始化一个runtime的硬件查询对象cudaDeviceProp,然后打印共享内存的大小。这里打印出来的内容只截取了每条命令的部分,主要给出中间的生成文件。
//打印信息
gcc -D__CUDA_ARCH__=200 -E -x c++ ... -o "test.cpp1.ii" "test.cu"上面这一步是device代码预处理,它将一些定义好的枚举变量(例如cudaError)、struct(例如cuda的数据类型float4)、静态内联函数、extern “c++”和extern的函数、还重新定义了std命名空间、函数模板等内容写在main函数之前。
cudafe ... --gen_c_file_name "test.cudafe1.c" --gen_device_file_name "test.cudafe1.gpu" ...这一步test.cpp1.ii被cudafe切分成了c/c++ host代码和.gpu结尾的device代码,其中main函数还是在.c结尾的文件中。
gcc -D__CUDA_ARCH__=200 -E -x c ... -o "test.cpp2.i" "test.cudafe1.gpu"
cudafe ... --gen_c_file_name "test.cudafe2.c" ... --gen_device_file_name "test.cudafe2.gpu"
gcc -D__CUDA_ARCH__=200 -E -x c ... -o "test.cpp3.i" "test.cudafe2.gpu"
filehash -s "test.cpp3.i" > "test.hash"
gcc -E -x c++ ... -o "test.cpp4.ii" "test.cu"
cudafe++ ... --gen_c_file_name "test.cudafe1.cpp" --stub_file_name "test.cudafe1.stub.c"上面这段生成的test.cpp4.ii是在对host代码进行预处理,前面几行内容直接看文件有点看不出来,希望以后能够把这段补充起来。
cicc -arch compute_20 ... --orig_src_file_name "test.cu" "test.cpp3.i" -o "test.ptx"
----------------
test.ptx:
.version 4.1
.target sm_20
.address_size 64
----------------
test.cpp1.ii
".../include/sm_11_atomic_functions.h"
...
".../include/sm_12_atomic_functions.h"
...
".../include/sm_35_atomic_functions.h"test.ptx文件中只记录了三行编译信息,可以看出对应了上面提到指定ptx的版本,以后可以根据这个版本再进行编译。实际上在host c++代码即每一个test.cpp*文件中,都包含了所有版本的SM头文件,从而可以调用每一种版本的函数进行编译。
ptxas -arch=sm_20 -m64 "test.ptx" -o "test.sm_20.cubin"这一步叫做PTX离线编译,主要的目的是为了将代码编译成一个确定的计算能力和SM版本,对应的版本信息保存在cubin中。
fatbinary --create="test.fatbin" ... "file=test.sm_20.cubin" ... "file=test.ptx" --embedded-fatbin="test.fatbin.c" --cuda这一步叫PTX在线编译,是将cubin和ptx中的版本信息保存在fatbin中。这里针对一个.cu源文件,调用系统的gcc/g++将host代码和fatbin编译成对应的目标文件。最后用c++编译器将目标文件链接起来生成可执行文件。
5. 小结
上面谈到了关于cuda软件层面的一些东西,内容也不算多,主要是谈谈自己对这方面的理解,最后的编译流程,具体每一步到底做了什么还不够清晰,希望能有人共同探讨一下。
参考:
[1] Lecture 1: an introduction to CUDA
[2] 【GPU编程系列之三】cuda stream和event相关内容
[4] Thrust