本文主要理解CUDA streams和相关的概念,有的概念翻译成中文反而无法体现它的意思,因此基本上还是用英文。主要参考了《The CUDA Handbook》这本书。
contexts
首先介绍contexts,它类似于cpu中的进程,它作为一个容器,管理了所有对象的生命周期,大多数的CUDA函数调用需要context。这些对象如下:
所有分配内存
Modules,类似于动态链接库,以.cubin和.ptx结尾
CUDA streams,管理执行单元的并发性
CUDA events
texture和surface引用
kernel里面使用到的本地内存(设备内存)
用于调试、分析和同步的内部资源
用于分页复制的固定缓冲区cuda runtime(软件层的库)不提供API直接接入CUDA context,而是通过延迟初始化(deferred initialization)来创建context,也就是lazy initialization。具体意思是在调用每一个CUDART库函数时,它会检查当前是否有context存在,假如需要context,那么才自动创建。也就是说需要创建上面这些对象的时候就会创建context。创建的这个context的特性跟程序之间给的要求有关,例如cudaSetDevice()(线程设置当前的context,这个函数并不需要context存在),cudaSetDeviceFlags()等。此处,可以显式的控制初始化,即调用cudaFree(0),强制的初始化。cuda runtime将context和device的概念合并了,即在一个gpu上操作可看成在一个context下。因而cuda runtime提供的函数形式类似cudaDeviceSynchronize()而不是与driver API 对应的cuCtxSynchronize()。应用可以通过驱动API来访问当前context的栈。与context相关的操作,都是以cuCtxXXXX()的形式作为driver API实现。
当context被销毁,里面分配的资源也都被销毁,一个context内分配的资源其他的context不能使用。在driver API中,每一个cpu线程都有一个current context的栈,新建新的context就入栈。针对每一个线程只能有一个出栈变成可使用的current context,而这个游离的context可以转移到另一个cpu线程,通过函数cuCtxPushCurrent/cuCtxPopCurrent来实现。
1.CUDA streams
CUDA streams用来管理执行单元的并发,在一个流中,操作是串行的按序执行的,但是在不同的流中操作就可以同时执行,从而完成并发操作。其中包括如下一些操作:
管理GPU、CPU的并发
当流处理器在执行kernel时可以调用内存复制引擎同时进行内存复制
(不同?)核函数的并发
多GPU的并发并发的例子如下[1],代码1下面的操作就是同步的,没有异步的过程
cudaMalloc ( &dev1, size ) ;
double* host1 = (double*) malloc ( &host1, size ) ;
…
cudaMemcpy ( dev1, host1, size, H2D ) ;
kernel2 <<< grid, block, 0 >>> ( …, dev2, … ) ;
kernel3 <<< grid, block, 0 >>> ( …, dev3, … ) ;
cudaMemcpy ( host4, dev4, size, D2H ) ;而代码2的操作是异步的,全并发的,在不同的四个流中完成不同的操作。
cudaStream_t stream1, stream2, stream3, stream4 ;
cudaStreamCreate ( &stream1) ;
...
cudaMalloc ( &dev1, size ) ;
cudaMallocHost ( &host1, size ) ;
…
cudaMemcpyAsync ( dev1, host1, size, H2D, stream1 ) ;
kernel2 <<< grid, block, 0, stream2 >>> ( …, dev2, … ) ;
kernel3 <<< grid, block, 0, stream3 >>> ( …, dev3, … ) ;
cudaMemcpyAsync ( host4, dev4, size, D2H, stream4 ) ;
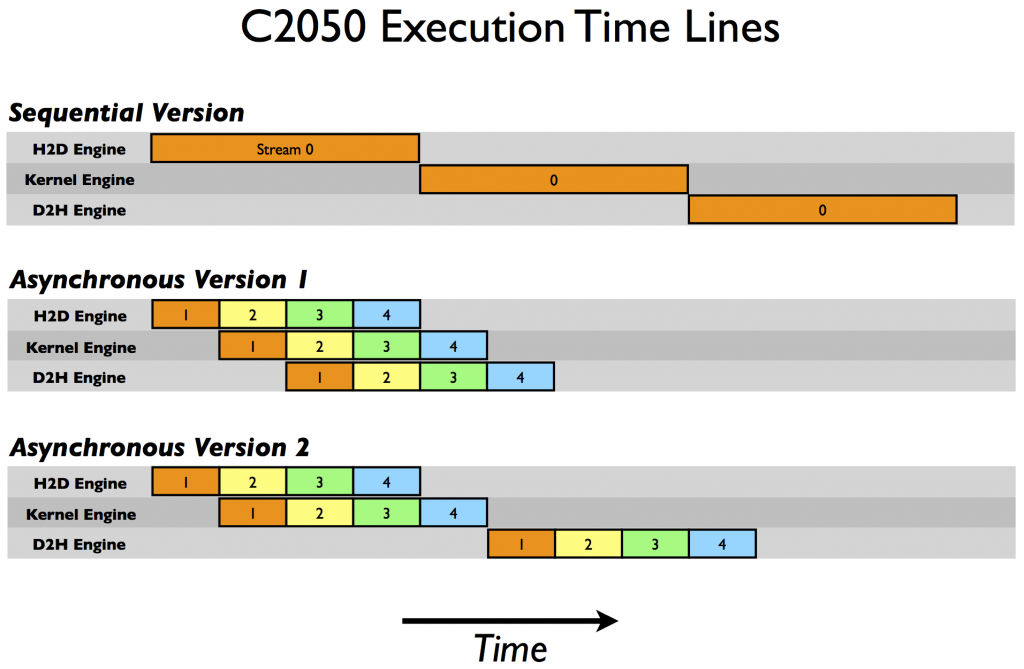
...同步异步的过程可以参考下图,其中的数字就代表了流编号。在第一张示例中,在一个stream 0上三个操作按序执行,第二张图中,第二个时间段,stream 1的kernel执行操作就和stream 2的内存复制操作时间重叠(overlap)了,从而做到了并发。
摘自http://devblogs.nvidia.com/parallelforall/how-overlap-data-transfers-cuda-cc/
GPU上的一些操作是异步进行的,异步的意思就是gpu在它执行完任务之前就将控制全返回给主机线程,那么就能保证后面的cpu程序在执行的时候gpu的函数也在执行。也就是说在GPU上执行的一些操作和CPU上执行的函数能够异步进行。这些操作大致如下:
启动核函数
在同一个设备上的内存复制
小于64KB内存从主机复制到设备
后缀带有Async的复制函数
调用内存设置函数(设置共享内存、L1缓存大小等)在cuda7版本之前,没有显式指定流,空流(默认流)会被隐式指定,它要同步设备上的所有操作。一个设备会产生一个空流。其它流的工作完成之后空流的工作才能开始,空流工作完成后其它流才能开始。cuda7版本增加了新的特性,可以选择每一个主机线程使用独立的空流,即一个线程一个空流,避免了原来空流的按序执行。http://devblogs.nvidia.com/parallelforall/gpu-pro-tip-cuda-7-streams-simplify-concurrency/
//启动每个线程一个空流的方法
//方法1
nvcc --default-stream per-thread
//方法2,在include CUDA头文件之前
#define CUDA_API_PER_THREAD_DEFAULT_STREAM2.CUDA events
CUDA events可以用来控制同步,包括cpu/gpu的同步、gpu上不同engine的同步和gpu之间的同步。此外可以用来检查gpu的操作时长。它能够向CUDA stream进行记录(record),cpu会等待event记录的这个地方完成才能执行下一步。
例如用来计算程序运行时间的例子,省略掉了初始化的过程。cudaEventRecord的第二个参数是cudaStream_t stream = 0 。
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i) {
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size,
size, cudaMemcpyHostToDevice, stream[i]);
MyKernel<<<100, 512, 0, stream[i]>>>
(outputDev + i * size, inputDev + i * size, size);
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size,
size, cudaMemcpyDeviceToHost, stream[i]);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);| 不同的同步函数原型 | 函数意义 |
|---|---|
| __host__ cudaError_t cudaEventSynchronize(cudaEvent_t event) | 等待event完成,才执行下一段 |
| CUresult cuEventSynchronize(CUevent hEvent) | 等待event完成,才执行下一段 |
| __host__ __device__ cudaError_t cudaDeviceSynchronize(void) | 等待device上所有操作完成 |
| CUresult cuCtxSynchronize(void) | 等待context中所有操作完成,driver API对应cudaDeviceSynchronize() |
| __host__ cudaError_t cudaThreadSynchronize(void) | 是cudaDeviceSynchronize的一个弃用版本,意义一样但是现在不用这个了 |
| __host__ cudaError_t cudaStreamSynchronize(cudaStream_t stream) | 等待传入的流中的操作完成 |
| CUresult cuStreamSynchronize(CUstream hStream) | 等待传入的流中的操作完成 |