Caffe是一个基于c++/cuda语言的深度学习框架,开发者能够利用它自由的组成自己想要的网络。目前支持卷积神经网络和全连接神经网络(人工神经网络)。Linux上,c++可以通过命令行来操作接口,matlab、python有专门的接口,运算支持gpu也支持cpu,目前版本能够支持多gpu,但是分布式多机版本仍在开发中。大量的研究者都在采用caffe的架构,并且也得到了很多有效的成果。2013年9月-12月,贾扬清在伯克利大学准备毕业论文的时候开发了caffe最初的版本,后期有其他的牛人加入之后,近两年的不断优化,到现在成了最受欢迎的深度学习框架。近期,caffe2也开源了,但是仍旧在开发。本文主要主要基于源代码的层面来对caffe进行解读,并且给出了几个自己在测试的过程中感兴趣的东西。
1.如何调试
为了能够调试,首先要在makefile的配置文件中将DEBUG选项设置为1,这步谨慎选择,debug版本会在打印输出的时候输出大量的每个阶段耗时,也可直接从整个项目的caffe.cpp入手来查看源文件。编译好可调试的版本之后,执行下面的指令可以启动调试。
gdb --args ./build/tools/caffe train –solver=examples/cifar10/cifar10_full_solver.prototxt调试过程中需要注意的一个问题是,源码中使用了函数指针,执行下一步很容易就跳过了,所以要在合适的时机使用s来进入函数。
2.第三方库
gflags是Google出的一个能够简化命令行参数处理的工具,在c++代码中定义实际意义,在命令行中将参数传进去。例如下面的例子中,c++的代码中声明这样的内容,DEFINE_string是一个string类型,括号内的solver就是一个flag,这个flag从命令行中读取的参数就会解析成string,存在FLAGS_solver中,使用时当成正常的string使用即可。在命令行调用时(参见调试部分举出的例子),用-solver=xxxxx,将实际的值给传递进去。这里的string可以替换成int32/int64/bool等。
*DEFINE_string(solver, “”, “The solver definition protocol buffer text file.”);*
需要注意的时,这个定义过程只能在一个文件中定义一次,其他文件要是想用的话可以有两种选择,一种是直接在需要的文件中declare,一种方式在一个头文件中declare,其他文件要用就直接include。声明方式如下:
*DECLARE_bool(solver);*
假如需要设置bool变量为false,一个简便的方法是在变量前面加上no,即变成-nosolver。此外,–会导致解析停止,例如下面的式子中,f1是flag,它的值为1,但是f2并不是2。
foo -f1 1 – -f2 2
Google Protocol Buffer(简称Protobuf)是Google公司内部的混合语言数据标准,目前已经正在使用的有超过48,162种报文格式定义和超过12,183个.proto文件。它是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化、序列化结构数据,自己定义一次数据如何结构化,目前提供了c++、java、python三种语言的API。相对于xml优点在于简单、体积小、读取处理时间快、更少产生歧义、更容易产生易于编程的类。
就caffe而言,这个工具的用处体现在生成caffe所需的参数类,这些类能从以.prototxt结尾的文件中解析参数,然后对应生成Net、Layer的参数。自己定义序列化文件a.proto,文件内容如图1,以关键词message来定义一个类,本图中它是卷积层的参数类,这个类的成员类型有bool和uint32等,也可用自己定义的类型。等号后面的数字是一个唯一的编号tag,来区分这些不同参数,在官方文档中这些称为field。可以在一个.proto中定义多个message,注释风格与c/c++一致。定义好的proto进行编译后生成.h和.cc对应c++的头文件和源文件。
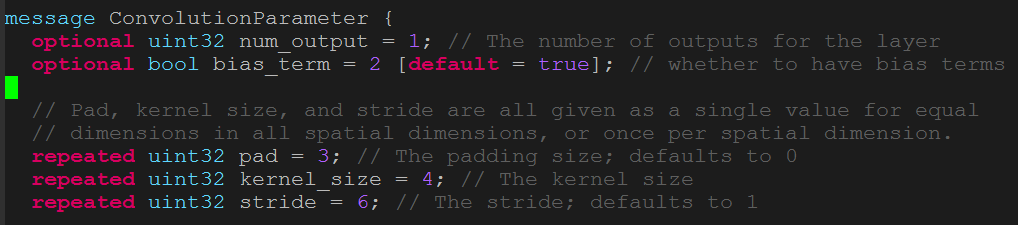
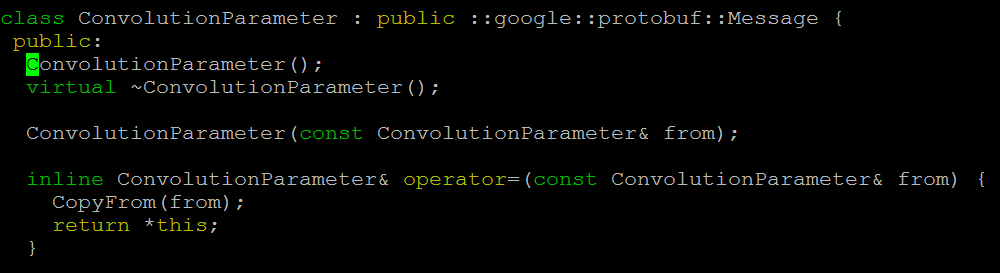
图2是编译后自动生成的文件,可以看到生成了ConvolutionalParameter类。
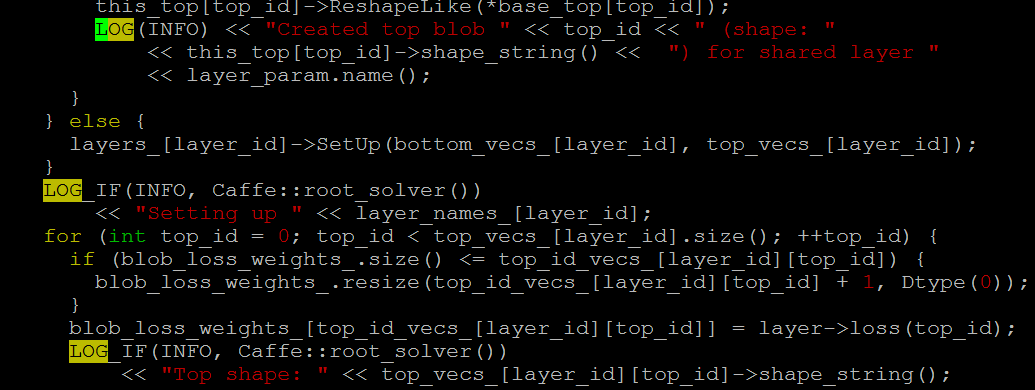
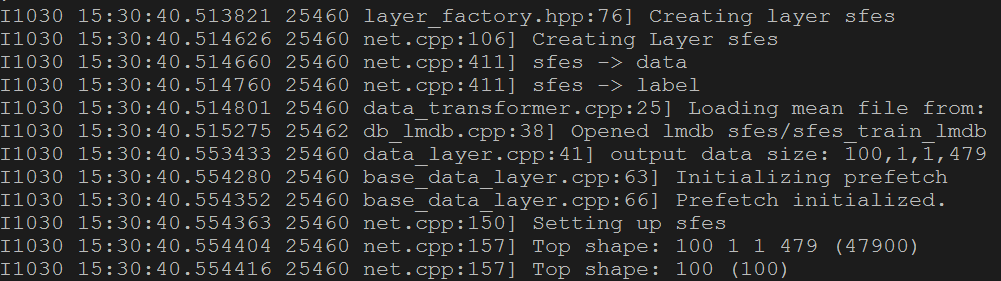
这个工具也是谷歌出品,用来打印初始化、运行时的信息,记录意外中断等。使用先要初始化google的logging库。一般在caffe中常见的LOG(INFO)…和CHECK(XXX)…都是它执行的。相关的内容可以参考下面的图片,图3是标出颜色的是代码中用到了的打印,图4是对应打印到屏幕上的信息。
lmdb是一个读取速度快、轻量级的数据库,支持多线程、多进程并发,数据由key-value对存储。caffe还提供leveldb的接口,本文只讨论python实现的lmdb。在这个数据库中存放的是序列化生成的字符串。caffe提供脚本文件先生成lmdb格式的数据,这个脚本文件会生成一个文件夹,文件夹下包括两个文件,一个数据文件,一个lock文件。然后调用训练网络的DataLayer层来读取lmdb格式的数据。图5是定义ldmb数据库类型,图6是将数据序列化再存入数据库中。


3.caffe基本结构
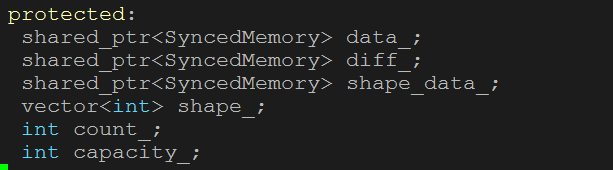
这是caffe的数据存储类blob,它实现了关于一个变量的所有相关信息和相关操作。存储数据的方式可以看成是一个N维的c数组,存储空间连续。例如存储图片是4维(num, channel, height, width),变量(n,k,h,w)在数组中存储位置为((n*K+k)*H+h)*W+w。相应的四维参数保存为(out_channel, in_channel, filter_size, filter_size)。blob有以下三个特征:
- 两块数据,一个是原始data,一个是求导值diff
- 两种内存分配方式,一种是分配在cpu上,一种是分配在gpu上,通过前缀cpu、gpu来区分
- 两种访问方式,一种是不能改变数据,一种能改变数据
其中让人眼前一亮的是data和diff的设计,其实在卷积网络中,很多情况下一个变量不仅有它自身的值,另外还有cost function对它的导数,采用过多的变量来保存这两个信息还不如将它们放在一起直观,下图是源码blob.hpp中的定义。
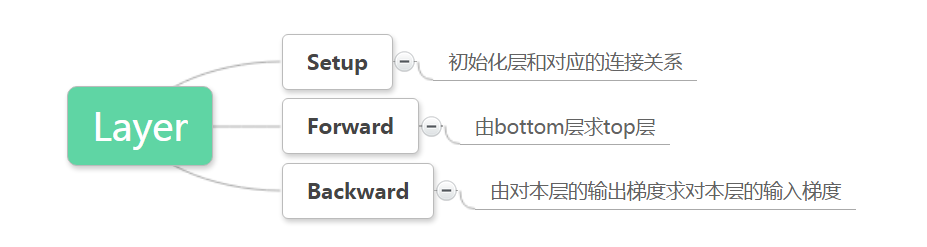
caffe根据不同的功能将它们包装成不同的Layer,例如卷积、pooling、非线性变换、数据层等等。具体有多少种layer及其内容参考官方文档即可,本文主要讨论它的实现,它的实现分为三个部分,也可参考演示图8:
- setup,初始化每一层,和它对应的连接关系
- forward,由bottom求top
- backward,由top的梯度求bottom的梯度,有参数的求参数梯度
而前向传播、后向传播的函数也分别有两种实现方式,一种基于gpu一种基于cpu。Forward函数,参数分别是两个存放blob指针的vector,分别是bottom、top。通过指针数组的方式能够实现多个输入多个输出。值得一提的是,caffe的卷积部分采用了将数据进行变换,变成矩阵之后再用矩阵乘法来实现卷积,cudnn也是采用这样的方式,经过我的实验,确实这种方式比直接实现cuda kernel要快一些。caffe大部分底层实现都是用blas或者cublas处理的。
Net它将不同的层正确的连接起来,是层和它们之间连接的集合。通过Net::Init()来初始化模型,构造blobs和layers,调用layers的setup函数。Net的Forward函数内部调用了ForwardPrefilled,并且调用了ForwardFromTo,它从给定的层数id(start)到end来调用Layer对象的Forward函数。
Solver是控制网络的关键所在,它的具体功能包括解析传递的prototxt、执行train、调用网络前向传播计算输出和loss、后向传播计算梯度、根据不同优化方式更新参数(可能不止有learning rate这种参数,而是由alpha、beta构成的更新方式)等。在解析.prototxt时,首先初始化NetParameter对象,用于放置全部的网络参数, 然后在初始化训练网络的时候,通过net变量给出的proto文件地址,来解析并获取网络的层次结构参数。其中的函数solve会根据命令行传递进来的参数来解析并恢复之前保存好的网络文件和权重等,恢复上次执行的iteration次数、loss等。当网络参数配置好,需要恢复的文件处理完成就调用net.cpp的Forward函数开始执行网络。Forward会返回这一次迭代的loss,然后打印出来。接下来会调用ApplyUpdata函数,它会根据不同的策略来改变当前权重的学习率大小,再更新权重。此外,solver还提供保存快照的功能。
4.运行实例
假如是自己的图片数据,可以按照如下的方法来进行分类。我全部采用的c++,改源代码比较方便。
- 将图片整理成train和test两个文件夹,并将图片的名称和label保存到一个txt中
- 将数据变成lmdb格式,采用的是convert_imagenet这个工具
- 生成均值处理后的图片,采用compute_image_mean这个工具
- 修改模型并执行train
此外,我还测试过一维数据,并且修改了convert_imagenet.cpp源码,将数据读入lmdb,大致代码如下:
datum.set_channels(num_channels);
datum.set_height(num_height);
datum.set_width(num_width);
datum.clear_data();
datum.set_encoded(false);
datum.set_data(lines[line_id].first);
datum.set_label(lines[line_id].second);通过改这个代码,可以将一维数据读入网络,进行处理。此外,在执行这个一维数据的过程中,也出了一个错,报错信息”Too big key/data, key is empty, or wrong DUPFIXED size”,这个问题是因为lmdb是保存的key-value对,而lmdb对key的长度进行了限制,长度不能超过512,但是我在传递的时候key的值给多了,因此得到了解决。
5.小结
通过阅读源码可以看到,caffe作为一个架构,层次、思路、需要解决的问题都非常清晰,它的高效体现在很多方面,不仅采用了读取快速的lmdb,而且计算部分基本上都是用很高效的blas库完成的。而它的数据、层次、网络的构成和执行是分开控制的,这点就提供了比较大的灵活性,唯一的遗憾就是安装比较繁琐,总是会出现某个依赖包没装好的情况。总的来说,caffe在科研领域使用的非常广泛,大量的研究都是基于caffe预训练好的imagenet的网络而得到了很好的进展,作者这种分享的精神值得肯定。